


Chapter 4 - Verifiable Off-chain Compute: Enabling an Instagram-like experience for Web3
Chapter 4: Use Cases of Co-Processors & Verifiable Off-chain Compute

Florian Unger (Principal, Florin Digital) | James Burkett (Partner, Florin Digital) | Feyo Sickinghe (Partner, Florin Digital)
A big thank you to Ismael (Lagrange Labs), Esli and Roshan (Marlin), Hang and Marvin (Phala Network) and their teams for invaluable help, review, and feedback.
Chapter 4: Use Cases of Co-Processors & Verifiable Off-chain Compute
Complete Table of Contents
Chapter 1: What are Co-Processors and why do we need them?
Chapter 2: Understanding the different types of Co-Processors (ZK and Optimistic Co-Processors)
Chapter 3: Understanding the different types of Co-Processors (TEE and Crypto-Economic Co-Processors)
Chapter 4: Use cases of Co-Processors & Verifiable Off-chain Compute
Executive Summary
Bringing verification to legacy operational processes will lead to efficiency increases and cost savings of >$300bn.
Verifiable off-chain compute introduces three groundbreaking paradigms: Trustless Data, Trustless Execution, and Trustless Privacy.
Trustless Data: Uses cryptography to secure the integrity of proprietary databases, dramatically reducing counterparty risk in B2B transactions.
Trustless Execution & Privacy: Enable autonomous processes, such as trustless AI inference, that continue uninterrupted and secure, while removing the need for third-party trust in ensuring data privacy.
Co-Processors are asset-light, software-based verification layers that integrate seamlessly with existing hardware, thereby benefiting from high gross margins and superior operating leverage.
Co-Processors enable a future built on cryptographic verification, where trust is mathematically guaranteed, not assumed.
We see cryptographic verifiability not just as a technical innovation; it is the next evolutionary leap in human interaction.
In previous chapters we discussed the limitations of decentralized systems, how Co-Processors can enable data-rich and compute heavy applications and we also touched upon different compute verification methodologies. In this final chapter, we will briefly summarize our past learnings and then focus on Co-Processor use cases; in particular Web3 use cases and their impact on Web2 equivalents.
Why this all matters: The market size of verifiable compute
To understand why we should care about verifiable compute, we need to grasp the quantitative value of verifiability. Admittedly, using cryptographic verifiability to reduce counterparty risk and fraud is an abstract concept, making it challenging to come up with a specific opportunity size. Finance and supply chain management is a great starting point as a lot of useful data is hidden in proprietary data silos. Today, counterparty risk is reduced either through reputation (which is risky and inefficient) or third-party assessments (which are costly). Verifiable compute can help break these silos, offering increased efficiency through transparency instead of blind trust.
Fraud Reduction: In 2023, global fraud losses amounted to $500 billion. So by how much could fraud detection through verifiability reduce this number? Judging by previous examples where technology has been able to reduce fraud (76% reduction in counterfeit fraud due to EMV chip technology in credit cards, 40% reduction in card-not-present fraud through real-time detection systems), even a conservative 5-8% reduction through verifiability could save $25-35 billion annually.
Payments and Automated Clearing House (ACH): In 2023, the Automated Clearing House (ACH) processed over $80 trillion across 30 billion transactions globally. At a 0.1% fee, this generates approximately $80 billion in transaction costs. If cryptographic verifiability could reduce costs by just 15%, that would represent a saving of $10 billion.
Financial Audits: In 2022, the average S&P 500 company had auditing fees of $10.8 million. By how much can this number be reduced through verifiability of siloed data? 10-15%? Looking at the global auditing market of $227 billion in 2024, we assume potential savings of $25 billion.
General Efficiency increase: How much efficiency do we gain from replacing “reputation-based” trust systems - which reinforce a global oligopoly due to "big equals safe" - with cryptographic trust systems giving smaller players verifiable guarantees, leveling the playing field and enabling more competition? Immeasurable.

Supply chain: The damages of counterfeits are estimated at $2.8 trillion per year. Supply chain transparency could realistically impact the 10-15% of items worth >$1k ($200 billion market). A 10% reduction in this market alone would result in $20 billion of savings. And what about the Testing, Inspection, and Certification (T, I & C) market for regulatory standards, currently valued at $359 billion? Cryptographic verifiability could improve the efficiency of these processes by 10%, which translates to savings of $35 billion annually.
Verifiable compute goes beyond creating trustless interactions; one of its core components, TEEs, enables two critical paradigms: trustless execution and privacy-enhanced computation. Both paradigms are increasingly prevalent in applications thanks to a new emerging trend:
Confidential Computing, whose market size is projected to rise from $7 billion in 2023 to $208 billion by 2032, showcases an eye-popping CAGR of 45%. The growth of confidential computing is driven by an increasing concern over data privacy and security in cloud computing environments.

30 second recap: Stateless Co-Processors bring more compute into Blockchains
All blockchains struggle with on-chain data storage and on-chain high- performance computation. This is known as the “scalability trilemma,” referring to the trade-offs of decentralized systems. This means there is a significant technical hurdle to building data-rich, performant Web3 applications. In order to build those superior applications, blockchains need to be able to access data-heavy, high-performance computation and storage just like their Web2 counterparts can. We have written about this extensively in Chapter 1, which you can find here.

Blockchains can be made more performant in two key ways: a) increase “on-chain” hardware requirements or b) outsource computation to “off-chain” actors. Increasing hardware requirements is not really viable as current applications already demand more compute power than any blockchain has on offer.
We can, however, outsource compute to trustless actors, whereby the correctness of the off-chain computation can be proven via some cryptographic or crypto-economic proof (this is colloquially called a verification method).

When talking about trustless “off-chain” compute, we differentiate between “stateful” (i.e. Roll-Ups) and “stateless” (i.e. Co-Processors, note that Co-Processors can hold limited state but for simplicity we have grouped them this way).
Co-Processors can be categorized based on their on-chain verification methodology. Zero-Knowledge (ZK) provides cryptographic verification, Trusted Execution Environment (TEEs) and Optimistic (OP) verification use mathematical means, and Crypto-Economic (CE) Co-Processors leverage economic incentives. We have written about ZK and Optimistic Co-Processors in Chapter 2 and about TEE and CE-Co-Processors in Chapter 3.
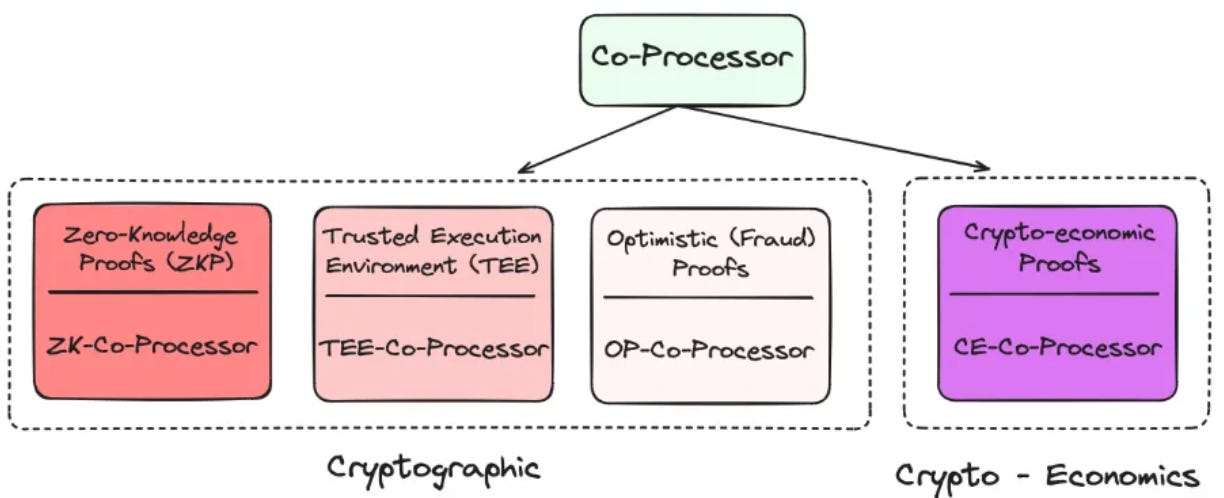
We have also written extensively about which type of Co-Processor is the most relevant for each application. This can be found here.
Why this all matters: Use cases of Co-Processors
When exploring use cases, we will use the following framework: new technologies are catalysts for creating new design spaces, which in turn lead to innovative solutions for existing business problems.

Confused? Let’s look at a straightforward example: the technological invention of the Simple Mail Transfer Protocol (SMTP) enabled email, transforming global communication. This new design space revolutionized business interactions, ultimately enhancing productivity across industries. The same can be applied to verifiable off-chain compute. By leveraging cryptography, Co-Processors create a new design space where “any digital compute operation can be outsourced in a verifiable and trustless way” rather than outsourcing based on trust and reputation. With additional technology integrations (i.e. AI, IoT), physical operations can also be made trustless (e.g. monitoring physical operations with cameras/IoT and AI).
We believe that just as the SMTP protocol massively changed actual business processes, we will see significant business improvements through the usage of Co-Processor protocols.
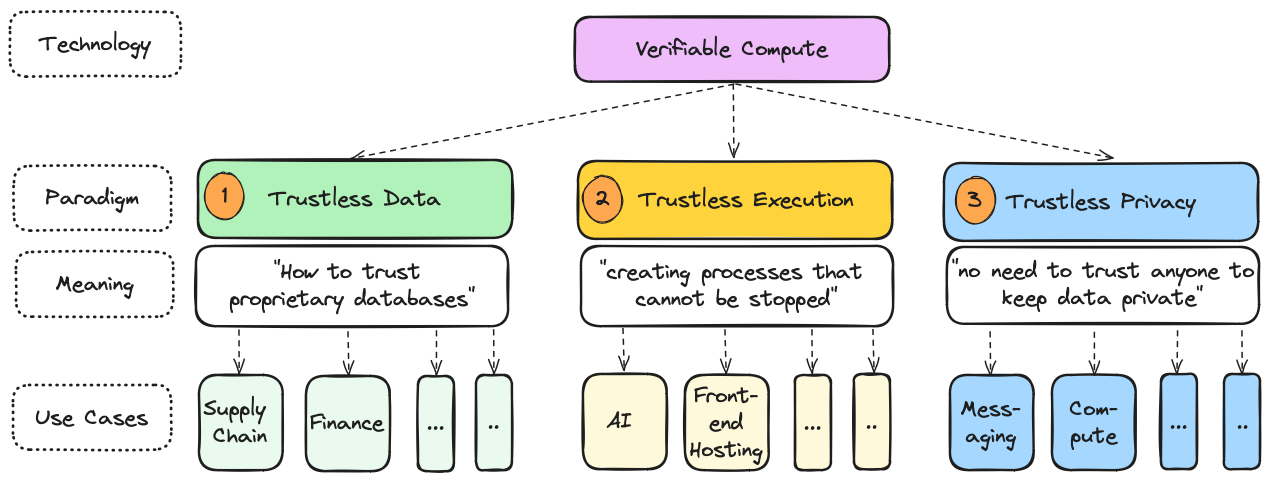
Going forward, we will discuss how new paradigms will lead to new use cases (Note: Please keep in mind that today some of the ideas presented are in the early stages of testing for technical feasibility. Furthermore, this list is not exhaustive.)
Paradigm #1: How to trust proprietary databases (Trustless Data)
Blockchain databases which rely on global consensus have three properties:
Append only: Data is immutable leading to an “append-only logic”.
Always available: Data is available and shared across multiple nodes. This means that it is impossible by a single party to deny something has happened. In contrast to when data is stored by a single entity (e.g. Web2 database).
Ordered: Blockchain data is inherently ordered, ensuring transactions are processed in a specific sequence. Ordering is crucial for maintaining operational integrity, ensuring business processes run smoothly and reliably.
These properties are made possible by global consensus. Blockchains can theoretically exist without global consensus, and they do, but in that case they are really just a glorified, auditable database.

Why is this relevant? In a traditional Web2 database, correctness is not mathematically guaranteed but rather based on trust and historical reputation requiring all parties to be fully trusted - a system vulnerable to manipulation and forgery. This means that any communication between 2 actors (businesses, governments, users) is based on trust, rather than mathematical guarantees. While this might be fine for some, counterparty risk represents a fundamental problem for others. So, how can we bring these three key properties (immutability, availability, and order) to Web2 businesses (relying on standard databases), reducing their counterparty risk while increasing efficiency and trustlessness?
This is what a solution could look like:
Auditor Verification: An auditor (think financial auditor) confirms the accuracy of the trusted database, taking a snapshot at a specific point in time. The auditor could themselves put up some collateral, making sure that they are not acting maliciously.
Proof Creation: A verifiable proof (i.e. ZKP) is generated off-chain using a Co-Processor based on the verified data from the auditor-approved database.
Public Presentation: The proof is presented to the public, ensuring transparency and security (and thereby confidence). To accomplish this, we mix cryptography with traditional Web2 trust elements.
This new design space of trustless Web2 databases is achieved by integrating Web3's cryptographic elements with Web2’s trust elements, in our example an external trusted auditor.

I know what you (as the technically-minded reader) are thinking “Hold on a minute! Is this not the same thing as TLS Notary?”. TLS Notary provides cryptographic proof that data retrieved from a secure TLS session is untampered and authentic, enabling the usage of Web2 data in Web3. As an aside, a TLS session is any type of data transmitted over the Transport Layer Security (TLS) protocol, including web traffic (HTTPS), emails, etc. While this works for the aforementioned data types, it does not work for data in proprietary Web2 databases since a typical database does not provide any HTTPS access. Because of this, there is indeed the need for the auditor verification system described above.

In Web3, this auditor verification method is currently used for a niche use case: Centralized Exchange’s Proof of Reserves. We envision how this process can be extended to Web2 enabling cheap B2B communication without counterparty risk.
When assessing counterparty risk, we focus on two key parameters: value and frequency. The auditor framework is particularly effective in high-value, high-frequency transactions where the middleman can be replaced by a cryptographic proof.
For one-off, high-value transactions, a trusted third party is often used to supervise the transaction (e.g., selling something on eBay, where the post office handles logistics and insurance). If something goes wrong, you can hold the third party accountable.
For one-off, low-value transactions, the risk is minimal, so insurance or third-party involvement is usually unnecessary (e.g., sending a postcard).
For recurring, low-value transactions, using a trusted third party may be too expensive, so businesses might take the risk, hoping for the best (e.g., drop-shipping low-value SKUs).
For recurring, high-value transactions, trust alone is insufficient due to the high stakes involved. While using a third party is too costly, some form of proof is necessary to mitigate risk. This is where the auditor framework, combined with cryptography, becomes invaluable (e.g. in the pharma supply chain, art trading, or key supplier relationships).
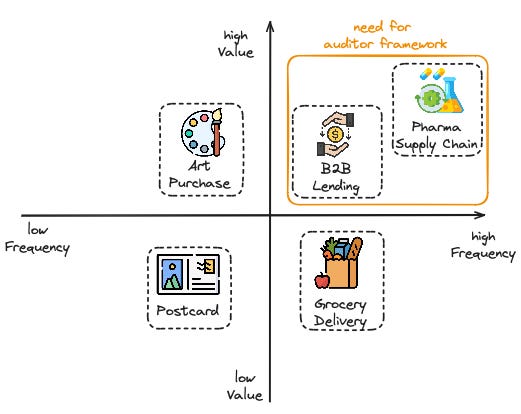
Business-to-Business: Today, most B2B relationships rely on trust, which generally works well. However, there are countless situations where cryptographic guarantees in the form of the verification framework could make communication and transactions more secure and efficient.
Supply chain Integrity: In high-value industries with fragmented supply chains (i.e. pharma, defense, art/luxury goods), maintaining the integrity of procurement and storage is critical. Many times items must be stored according to precise requirements (i.e. temperature, location). These parameters are collected via IoT devices and stored in proprietary databases. Downstream suppliers and customers must trust that the data is accurate and unmanipulated. By applying the auditor framework discussed above, this critical data can be periodically vetted by a 3rd party and shared in a cryptographic way with counterparties, enhancing confidence in the entire system.
Example 1 - Aerospace industry: Annually, 520 counterfeit parts enter aircraft (2% of total parts), costing $10 billion. This could be reduced with the proposed verification framework.
Example 2 - Art storage: Proper art storage conditions can be monitored and verified using the framework, providing proof to third parties.
Example 3 - Pharma / wine storage: Similar to art, the framework ensures that storage conditions for pharmaceuticals and wine are monitored and verifiable.
Financial transactions: In financial transactions, counterparty risk is often mitigated in one-off, high-value trades by using a middleman or market maker. For recurring transactions, risk is typically managed through reputation, favoring large, well-known banks, which creates an oligopoly where "big equals safe." Introducing operational transparency through cryptographic proofs (auditor framework) allows smaller financial actors to offer strong, verifiable guarantees, leveling the playing field and enabling them to compete with larger institutions. This shift reduces reliance on reputation alone and promotes greater competition in the financial sector.
Government-to-Government: Global challenges like nuclear proliferation and climate change require coordination between governments that may not fully trust each other. Cryptographic proofs provide a way to collaborate without needing trust.
Nuclear inspections: Traditionally, the IAEA monitors critical nuclear data (e.g. enrichment levels, performances of centrifuges) to prove nuclear compliance. These data points are primarily stored in the proprietary databases of the inspected countries. However, there are challenges—inspected countries may be reluctant to share data, and third-party nations might distrust it due to its proprietary nature. To address this, the IAEA could use the auditor framework to vet the data and generate cryptographic proofs, which are then shared with third parties, enabling bigger confidence inside the nuclear community.
Paradigm #2: How to create processes that cannot be stopped (Trustless Execution)
Trustless Execution ensures that processes within a TEE are fully protected by the wrapper, preventing interference from both the program developer and the compute host. In Web3, TEE implementations have become increasingly common, allowing developers to achieve trustless compute operations:
TEE wrappers are used for defense in depth, which is a multi-layered security approach to protect critical components inside MPC (Multi-Party Computation), Bridges, or Threshold FHE Key Management Nodes.
Decentralized front-ends are significantly more resilient against DDoS attacks, malicious takeovers, and other threats that have plagued centralized front-ends of dApps for years. TEE-wrapped front-ends offer an upgrade over IPFS-saved static front-ends, providing the necessary backend functionality for dynamic dApps. In addition, they are censorship-resistant, crucial for billions in developing countries (e.g. X being banned in Brazil).
Another key use case are trustless Web2 to Web3 oracles, where the API sits inside a TEE, enabling secure data transfer between Web2 and Web3 or even between different Web2 systems.
Replacing MEV-boost relays with TEE-boost: Rather than relying on centralized relays to connect proposers with a market of block builders, Shea from Flashbots has proposed TEE Boost, which lets proposers accept blocks directly from block builders running in TEEs.

In Web2, we have seen an increased usage of TEEs to achieve trustlessness.
Trustless AI Inference: We can run AI scripts inside a TEE to ensure model integrity. Using TEE alone can avoid manipulation of AI input or output, but unless we make the full AI supply chain secure (i.e. how the model is trained and loaded to the GPU), it cannot ensure the models are unbiased and reliable. The most notable company in this segment is Phala Network.

Tamper-Proof Algorithms: We can host AI or web algorithms within TEEs to ensure they remain unaltered, preventing biases or unauthorized modifications. This is crucial for maintaining the integrity of processes such as search algorithms, where manipulation could serve political agendas or financial interests, like rerouting foot traffic through areas where businesses have paid for increased visibility.
Just as mentioned above in the Web3 section, Web2 applications could benefit from TEE-wrapped front-ends which are more resilient than their centralized equivalents.
Paradigm #3: How to eliminate the need to trust anyone to keep data private (Trustless Privacy)
In the last few years, we have seen the ongoing erosion of data privacy. TEEs offer a powerful remedy for enhancing server-side privacy, ensuring that nobody from the server side can monitor websites and online activity. In Web3, TEEs have been used in the past to enhance privacy:
For example, smart contract VMs have been placed inside TEEs to enable programmable privacy (TEE-wrapped VMs), as originally envisioned with the Secret Network.
Another innovative use is wrapping an AMM within a TEE to create a dark pool AMM or sniper-resistant lending, where privacy ensures that transactions cannot be preempted or sniped as both the router contract and pool operations remain hidden.
Additionally, TEE-wrapped block builders ensure trustlessness and compliance with rules while maintaining pre-trade and failed-trade privacy.

Also in Web2, we have seen numerous ideas and projects to use TEEs for additional privacy guarantees:
Collaborative AI training with privacy: Multiple parties can train models together within the TEE without sharing sensitive data with each other. This setup allows each party to contribute to the model while the TEE ensures that their data remains private.
Secure On-Premise AI Deployment with Encrypted Models: Another compelling use case involves encrypted AI models. For example, OpenAI could authorize a company to use GPT-4 on-premise within a TEE. This setup ensures that the company cannot steal the model, as it remains secure within the TEE, and OpenAI cannot spy on the company’s data since it resides in their data center. This approach enables customizable AI models for enterprises while maintaining strict privacy controls.
Confidential Cloud Computing: TEEs protect cloud services, enabling secure data processing in a shielded environment. This prevents unauthorized access by cloud providers, ensuring that user data remains confidential and secure. Furthermore, confidential computing can unlock computing scenarios that have previously not been possible.
Example 1 - private healthcare data: With the rise of healthcare trackers and remote self-care technologies that empower consumers, there is an increasing need for confidential computing to protect personal health information. Confidential computing ensures that sensitive data is securely processed within a protected virtual machine, maintaining user privacy and enabling the safe use of these innovative health technologies.
Example 2 - data clean rooms for marketing efficiency: Data clean rooms are secure environments where multiple parties can share and analyze data without exposing the underlying information. With the decline of third-party cookies, marketing effectiveness has suffered. Confidential computing enables these data clean rooms, allowing first-party data to be securely enriched with third-party data, improving targeting accuracy and maximizing return on ad spend (ROAS).
Example 3 - Data Sharing to Combat Money Laundering: Financial institutions must protect customer data while complying with AML regulations. Individual datasets often fail to detect suspicious activities, but aggregating data across institutions can expose illicit transactions. However, sharing such sensitive information with competitors introduces significant risks. Confidential computing allows secure data collaboration, enabling institutions to share and analyze data privately, helping detect money laundering without risking data exposure.

The business view: Co-Processors as asset-light verification layers
We are particularly interested in confidential computing, and here's why: Not only are there established use cases (as mentioned above), but major players like FAANG companies are already educating the market, making it easier for Co-Processor protocols to target these potential customers. This represents the most advanced example of blending Web2 with TEE Co-Processors. Let’s dive into the unit economics of a confidential cloud business and compare it with Marlin, a Web3 confidential cloud provider.
Co-Processors vs. Web2 counterparts: Business set-up
Marlin operates as an asset-light marketplace where hardware is outsourced, running in TEE containers secured by cryptographic methods. The unique aspect of verifiable compute is that the heavy-lifting is outsourced to hardware providers, while verification is handled through software. This makes Co-Processors fundamentally software-driven, allowing verifiability to be added as an efficiency layer without significant hardware investments.
Why does this matter? Unlike asset-heavy Web2 competitors, Marlin is more scalable and cost-efficient due to minimal capital expenditures (CAPEX) and no need for hardware replacement every 2-3 years. This gives Marlin higher operating leverage and better gross margins.
Asset-Heavy Web2 Cloud Providers:
Revenue: Capture 100% of revenue from services.
Costs: 100% internalized, as they own and operate their infrastructure, reducing gross margins to 59-65%.
CAPEX: Significant CAPEX is required for hardware, which needs to be replaced every 2-3 years, resulting in ongoing hardware depreciation.
Asset-Light Web3 Cloud Marketplace (Marlin):
Revenue: Earns a 10% commission on all - one-off and recurring - transactions
Costs: 99% externalized by paying external compute providers, allowing Marlin to flexibly source the cheapest resources. Many costs are paid in native tokens rather than USD, adding flexibility.
CAPEX: Minimal fixed costs and no significant CAPEX, enabling higher operating leverage and better gross margins.

This is why we are so excited about Co-Processors: their role as a simple verification layer that can seamlessly integrate into existing hardware and compute infrastructure through software—no need for massive CAPEX investments, just pure software that brings verifiability to the heart of any (compute) operation. With this, we replace the inefficiencies of reputation-based trust systems with cryptographic trust, unlocking massive cost savings and unprecedented efficiency.
When you step back and look at the bigger picture, you realize that the entire global bureaucratic system exists to prevent cheating and ensure compliance. And when that system falters, we fall back on reputation-based solutions. But there’s a better way—a future built on cryptographic verification, where trust is mathematically guaranteed, not assumed.
The impact? Potentially massive. In sectors like finance and supply chain management, we already see potential efficiency gains of over $200 billion, and this number will double as confidential cloud computing becomes more widespread. We believe that cryptographic verifiability is not just a technical innovation; it's the next evolutionary leap in human interaction, with Co-Processors being at the forefront of this transformation.
Next…
This brings us to the end of our Co-Processor Series, in which we have explained the need for verifiable off-chain compute, highlighted different verification methodologies, presented several exciting start-ups and explored use cases. Our conversations with builders and ongoing research leave us excited about the future of Co-Processors, and we will be closely following developments in the months and years ahead. If you'd like to connect, please feel free to reach out!
About Florin Digital

General Disclaimer
Florin Digital and its affiliates make no representation as to the accuracy or completeness of such information listed herein. These materials are not intended as a recommendation to purchase or sell any commodity, security, or asset. Florin Digital has no obligation to update, modify or amend this material or to otherwise notify any reader thereof of any changes.
This presentation and these materials are not an offer to sell securities of any investment fund or a solicitation of offers to buy any such securities. Any investment involves a high degree of risk. There is the possibility of loss, and all investment involves risk including the loss of principal.
Florin Digital LP and its affiliates may currently hold positions in tokens mentioned in this report, may have at one time held positions in tokens mentioned in this report, and may enter into spot, derivative, or other positions related to tokens mentioned herein.
Anything mentioned here should not be interpreted as a recommendation to purchase or sell any token, or to use any protocol listed, described, or discussed. The content of this report reflects the opinions of its authors and is presented for informational purposes only. This is not and should not be construed to be investment, tax, or legal advice.