


Chapter 2 - Verifiable Off-chain Compute: Enabling an Instagram-like experience for Web3
Chapter 2: The “Marketing Genius” (ZK Co-Processor) and the “Versatile Magician” (Optimistic Co-Processor)

Florian Unger (Principal, Florin Digital) | James Burkett (Partner, Florin Digital) | Feyo Sickinghe (Partner, Florin Digital)
A big thank you to Sylve (Hylé), Mo (Brevis), Paul (RISC Zero), Yi (Axiom), Ismael (Lagrange Labs) and their teams for invaluable help, review, and feedback.
In Chapter 1 we discussed why decentralized systems suffer from inferior compute and storage capabilities compared to centralized databases, prohibiting the effective deployment of data-rich applications. Several solutions exist today, one involving Co-Processors, and we believe it to be the most elegant solution to unlock “the Instagram experience” in Web3.
Chapter 2: The “Marketing Genius” (ZK Co-Processor) and the “Versatile Magician” (Optimistic Co-Processor)
In Chapter 2 and 3, we examine the technical differences between ZK, Optimistic, TEE and Crypto-economic Co-Processors, how they might work together to enable unprecedented compute and storage on blockchains, and how they can create new possibilities and primitives. Due to the length of the content, we will cover ZK and Optimistic Co-Processors in Chapter 2 and TEE and Crypto-Economic Co-Processors in Chapter 3, which will be released early next week.

PSA: We will paste the occasional meme in order to lighten up this tech-heavy section of the report.
Complete Table of Contents
Chapter 1: What are Co-Processors and why do we need them?
Chapter 2: Understanding the different types of Co-Processors (ZK and Optimistic Co-Processors)
The Categorization of Co-Processors
ZK Co-Processor (The Marketing Genius)
Case Studies (Axiom, RISC Zero, Lagrange)
Optimistic Co-Processor (The Versatile Magician)
Case Study (Brevis)
Chapter 3: Understanding the different types of Co-Processors (TEE and Crypto-Economic Co-Processors)
Chapter 4: Use cases of Co-Processors
Chapter 5: Open questions on the future of Co-Processors
Executive Summary:
Co-processors are primarily categorized by their on-chain verification methodology: Zero-Knowledge (ZK), Trusted Execution Environments (TEEs), Optimistic (OP), and Crypto-economic
ZK Co-Processors provide strong security guarantees but are hindered by slow and expensive computation, liveness issues, and limited use cases
Optimistic Co-Processors, a new architectural design, provide a wider range of use cases but remain unproven and relatively untested
The Categorization of Co-Processors
Despite being relatively new to the crypto world, Co-Processors can already be categorized in various ways. The prevailing method is based on their verification methodology. Given that Co-Processors execute tasks off-chain, they must ensure verifiability and correctness on-chain. This is achieved through two approaches:
Cryptographic Correctness: This method utilizes mathematics and cryptography to ensure the off-chain compute provider does not cheat. Techniques such as Zero-Knowledge Proofs (ZKPs), Optimistic Fraud Proofs, or Trusted Execution Environments (TEEs) are commonly employed.
Crypto-Economics: Leveraging economic incentives to prevent dishonesty, this method involves an economic bond which can be forfeited if cheating is detected.


While this is the current state of affairs, we anticipate that in the future classifications will shift towards specific use cases. Instead of ZK or TEE Co-Processors for example, we might see AI or gaming Co-Processors. This trend reflects the natural progression previously observed in other technological fields. Twenty years ago, we referred to generic processors like Intel’s Pentium and AMD’s Athlon. Today, we discuss specialized chips tailored for specific tasks, such as AI chips for deep learning or graphical processors for image rendering. This evolution towards function-based nomenclature highlights how industries mature and adapt to meet distinct needs more efficiently.

Going forward we will explore these verification methods (with examples), examine their pros and cons, associated costs, and original use cases. Understanding these aspects allows us to appreciate how these verification methods enhance the trustworthiness and efficiency that Co-Processors can bring to blockchain systems. At the same time, it furthers our understanding of which use cases in particular can benefit from Co-Processors in the near and distant future.
ZK Co-Processor (The Marketing Genius)
Co-processors leverage ZKPs to ensure the accuracy and integrity of off-chain computations. In essence, ZKPs allow one party (the "prover") to demonstrate to another party (the "verifier") that a given computation was executed correctly without repeating the original computation or disclosing the input or output. This means a single entity, such as a Co-Processor, can handle complex transaction processing off-chain and use a ZKP to verify on-chain that the computation was performed correctly. This is in stark contrast to say ChatGPT, where we need to trust that the OpenAI back-end has performed the computation correctly and that the content comes from verified sources rather than just being made up.

While this does not sound like a big issue today, it will be one in the future as we increasingly rely on AI generated content. With ZKPs, we could remove a trust assumption in ChatGPT models by verifying their outputs' validity and integrity, without exposing the underlying data or model specifics thereby ensuring privacy, security, and confidence in AI-generated responses. In other words, ZKPs enable trustless verification of any type of interaction. As ZKPs mathematically cannot lie, they represent an ideal verification methodology.

Advantages:
High security: ZKPs verify computations without revealing sensitive information or requiring re-execution, ensuring data integrity and privacy.
Well-understood technology: Extensive research, driving a 10x increase in annual academic publications over the past 10 years, has led to a deep understanding and acceptance of ZKPs as a verification methodology, contributing to their strong reputation and reliability in the market.
Enhanced utilization: Recent advancements, such as a 22x faster proving time, 13x smaller proofs, and 30x faster verifier times between 2017 and 2022, have made ZKPs more accessible and practical.
Data confidentiality: As a proof is created without revealing the input, the underlying data is kept private. This is true for client-side proof creation (i.e. on your phone), yet this differs from external proof creation which involves different data trust assumptions.
Disadvantages:
Computationally intensive: Despite recent advancements, ZKPs still require significant computational resources. Zero-Knowledge computations are 1,000 to 10,000 times more expensive than traditional computations. Specialized hardware (e.g. SNARK proving ASICs) can help reduce costs, but the high computational demand remains a barrier.


Expensive and Slow: Generating proofs can be both costly and time-consuming. For example, proving the trading volume of 1,000 Uniswap v3 transactions costs about $1.80, takes 144 seconds, and requires 8 servers with 4090 GPUs. This latency disrupts transaction flow and detracts from the user experience: nobody is willing to wait 3 minutes for a promo code. Long-term however, we do see proof composability (basically re-using existing proofs) offering potential cost reductions. Research on this topic is still early days though.
Limited use cases: ZKPs as a verification methodology are less effective at proving non-events. For example, let’s assume an application wants to prove that their user addresses have never interacted with an OFAC restricted entity such as Tornado Cash. The best way to do this using ZK Co-Processors, would be to look at all transactions of a certain address since Nonce 0 (aka the beginning of the Ethereum Blockchain), given the need to look at “indirect” transactions too. For every transaction, one needs to create an individual proof (“yes, this transaction is clean”). Assuming 1000’s of transactions, this would result in thousands of ZKPs, which would be too expensive and unworkable. In summary, ZKPs excel at proving the existence of an event but struggle with proving non-existence.
Dependency on secure data provenance: The effectiveness of ZKPs depends on the integrity of the entire supply chain. Introducing new data into the chain of provenance requires another ZKP, adding complexity and potential vulnerability. For example, a ZK Co-Processor that fetches data from a centralized API such as the Twitter API to obtain the follower count of a specific account, will need to perform all computations inside a “ZK compute environment”, including the HTTPS connection to Twitter, parsing the JSON response, and transforming the data to EVM ABI encoded format. Low-quality ZK projects only handle data transformation, more complex projects handle parsing and transformation, but very few projects today cover the entire process from connection to transformation.

Liveness issues: ZKPs can face liveness issues, affecting their ability to serve mission critical use cases. Imagine being unable to prove billions of dollars worth of (equity) trade settlements because the proof generator is unavailable, just like most European administrative institutions after 4pm on a Tuesday. These issues can arise from low computational capacity, slow proof generation, network disruptions, resource exhaustion, prover failures, or Denial-of-Service (DoS) attacks. Potential solutions include crypto-economic guarantees or open-sourcing the prover to create prover networks (e.g. Gevolut) or marketplaces (e.g. Nil). These measures help address liveness issues, similar to those seen in blockchains, ensuring ZK Co-Processors remain functional.

To prove computational integrity (aka to compute in a “ZK-way”), we need to input normal compute programs into a “ZK Processor machine”, which executes the compute and puts it into a wrapper which proves the computation has been executed correctly. Over the years, we have seen the development of two types of ZK Co-processors: (a) specialized Co-Processors and (b) general compute Co-Processors.

Specialized Compute Co-Processors (aka Custom Circuit): Custom Circuits are designed for a specific purpose. For example, an app developer wants to calculate a “user loyalty score” based on how many interactions they have had with the app. Since the scope of this type of program is very narrow, the circuit can be designed and optimized for this specific computation. To achieve the best performance, the programs are written in ZK-specific languages and compiled into purpose-built circuits.
General Compute Co-Processors (aka stateless zkVM): These Co-Processors allow programs written in mainstream programming languages (like Python, json, etc.) to be compiled into a virtual machine (VM) for execution. For example, RISC Zero's zkVM runs RISC-V bytecode, so it can support any language that can be compiled to RISC-V (e.g. Rust, C, C++). In addition, RISC Zero currently offers support for Rust, and is planning to add support for additional languages. This means that zkVMs will be able to handle more generalized computation. For example, you could run a full Linux operating system in a zkVM Co-Processor and verify software integrity. However, compared to a Custom Circuit, the zkVM approach can be less efficient.

Initially, the Custom Circuit approach was predominant within ZK Co-Processor development. Axiom is a notable example, focusing on niche applications such as providing smart contracts with access to historical state data in a verifiable way. In practice, this could allow Uniswap smart contracts to offer real-time rebates to users commensurate with their on-chain activity, similar to Uber offering discounts to loyal users. This is a typical example of the Instagram-like user experience Web3 apps so dearly need.
Case study: RISC Zero’s Bonsai
Recent efforts have pivoted towards the zkVM approach, which offers more general ZK computation, and Bonsai from RISC Zero exemplifies this approach. Bonsai operates as a ZK proving service, with RISC Zero proving zkVM computation on demand. Over time, Bonsai will become more of a proving marketplace, which will allow for 3rd-party hardware operators to step in as proof providers. Bonsai’s proof marketplace also includes options for privacy-enhancing client-side proving, thereby offering maximal flexibility when it comes to proving your computation.
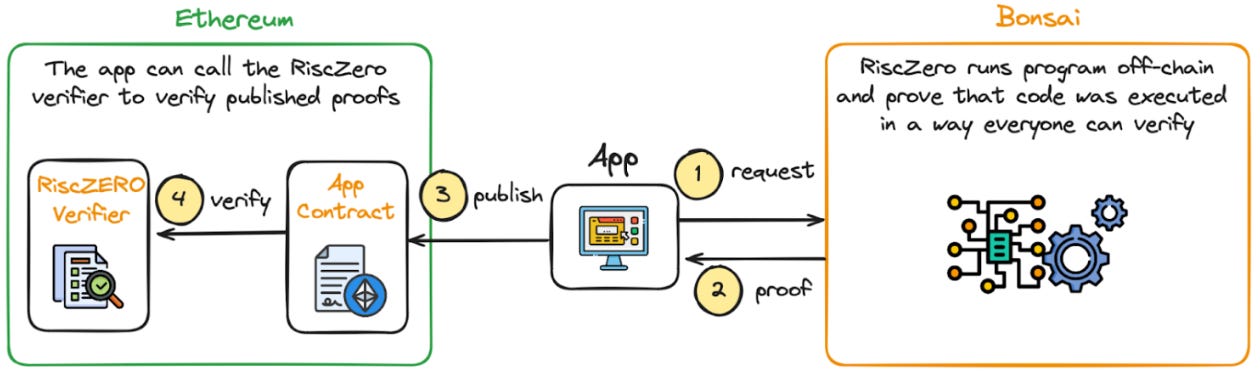
The resulting proof can be verified either by the RISC Zero verifier or an independent verifier on any chain. As the verification process can be relatively costly, RISC Zero is offering proof recursion, whereby proofs are aggregated to be submitted as batches. RISC Zero offers a plug-and-play API that allows users to aggregate proofs and develop arbitrary zkVM applications to verify proofs from other zkVM applications.
This vertical integration of the ZKP creation and verification supply chain - internalizing the proof creation, the proof recursion and the verifier contracts - illustrates the protocol’s comprehensive approach to ZKPs. The vertical integration and the underlying business model will be further discussed in Chapter 4 of this report.

Case study: Axiom
While RISC Zero focuses on a more general-purpose stateless zkVM, Axiom leads the way in specialized compute Co-Processors, also known as Custom Circuits. As previously discussed in Chapter 1, smart contracts on Ethereum cannot access historical state data without increased hardware requirements, which in turn would compromise decentralization. On Opensea, for example, only the information of the current owner is stored on chain for other smart contracts to access. All past historic information is stored on archive nodes managed by semi-decentralized organizations, which is suboptimal as they insert new trust assumptions. Axiom’s revolutionary idea is to scale historical data and computation for smart contracts in a trustless manner, relying on verified off-chain compute. Axiom is considered by many to be a pioneer of Co-Processors in Web3.
This is how it works: Applications specify a query to Axiom by writing a client circuit, requesting verified computation using Ethereum historical data. This circuit can be written in Typescript using the Axiom SDK, making it accessible for developers without ZK expertise. To receive Axiom query results in your smart contract, an Axiom-specific callback function needs to be implemented. Subsequently, the client circuit's query is sent to the Axiom circuit which retrieves the historical data and performs the necessary computation to generate a ZKP. This ZKP validates that the computation was executed correctly. The ZKP is then submitted on-chain and the result is sent back to the client circuit, making it available for use by the smart contract of the specific application.

This enables smart contracts to read various pieces of historical data such as block headers, account balances, and storage slots. It also allows for the retrieval of an account balance in one block and a token balance in another block, facilitating a wide range of trustless computation and data verification on Ethereum. Overall, Axiom’s technology enables a wide variety of applications and use cases to interact with data in a trustless manner. More examples will be discussed in Chapter 4, which focuses exclusively on Co-Processor use cases.

Case study: Lagrange Co-Processor
One of the most novel projects in the ZK Co-Processor space is Lagrange’s ZK Co-Processor. Their goal is to create a provable database containing a subset of original blockchain data that can be efficiently queried. This means that rather than running compute inside a zkVM or a Custom Circuit, a new provable database is created out of the “difficult to compute” blockchain database. This set-up allows smart contracts to run intensive computations off chain which can be efficiently verified on chain. To achieve this goal, the Lagrange ZK Co-Processor works in two phases:
Phase #1 - Pre-Processing: Blockchain data inside the EVM is challenging to compute due to the complexities of Merkle Patricia Tree (MPT) structures, Recursive Length Prefix (RLP) encodings, and Keccak hash functions. The time required for computations increases commensurately with the depth and complexity of historical data. For instance, going back 10,000 blocks necessitates over 10,000 hash function computations, practically limiting computational queries. Lagrande solves this problem via Pre-Processing.
The Pre-Processing phase involves several key steps. First, it transforms the existing data within a commitment into a new structure and proves that this new structure is equivalent to the original data. Next, it updates this proof of equivalence to ensure that queries can be served cheaply and efficiently over the transformed data source. Essentially, this step is about indexing the contract’s storage at each block and inserting this data into a verifiable database. This process allows for efficient and provable queries. Today, this process is computationally intensive as most blockchain data structures are not designed to be easily proven or queried. With Lagrange, the Pre-Processing of over a million storage slots takes 1 minute.

Phase #2 - Running Queries: Once the data is pre-processed, provable SQL queries can be run in parallel over the new database each time a smart contract requests it. This computation design is inspired by the MapReduce model (a programming model for processing large data sets).
The transformed data must then be organized into a meaningful structure, such as grouping all Uniswap v3 swaps over the last 10,000 blocks. It is crucial to structure the data in a way that allows access to a significant number of slots and to perform computations that return results interpretable by smart contracts. Essentially, this method works like SQL over provable data, enabling you to take the pre-transformed structure, run computations, prove these computations in parallel across a series of nodes, and compose and recursively combine these proofs for on-chain verification. A query costs around $0.05-0.1 with a proving time of ~6-8 seconds. Similar to the capabilities of Dune (a blockchain data query and visualization service), this process allows you to verifiably consume on-chain data within your smart contracts. However, with Dune, the users have to trust that Dune has accurately fetched and indexed Blockchain data. The moment Dune changes their indexing, users are left without any access to Blockchain data. This risk does not exist with Lagrange’s trustless approach. By leveraging Lagrange’s approach, computations can be efficiently run and verified, ensuring robust and trustworthy results on chain.

“Why is ZK Co-Processing and Verifiable Off-chain compute relevant?”, I hear you ask. As we have established in Chapter 1, the concept of verifiability and trustlessness is becoming increasingly important in a world of ubiquitous data and AI. Therefore, proving origin and the correctness is paramount. As an example, one could prove the correctness of an AI-generated customer service bot without having to disclose its training data and model parameters. This would be achieved by “inserting” the AI customer service bot into a zkVM Co-Processor, which is not only running the compute, but also proving that the AI bot did not “maliciously” work against the user. In the future, we will see bigger compute operations (e.g. LLMs) being put inside zkVMs - something that is currently economically infeasible due to the cost overhead of ZK compute.
More feasible today for example, would be the process of running a loan application (or any type of application) inside a zkVM to prove that applicants are evaluated equally and fairly (e.g. without favoring specific ethnicity). Long-term, we believe that any digital process where one party has the opportunity to cheat and gain an advantage, will be run in some form of zkVM to install cryptographic guarantees of correctness.
Optimistic Co-Processor (The Versatile Magician)
While the ZK model for Co-Processors offers simplicity and a trustless framework, it has its own set of drawbacks. As discussed, ZK Co-Processors face limitations around computationally intensive use cases and speed. These limitations, if left unaddressed, make ZK Co-Processors impractical for many low-value and low latency applications, particularly those involving large amounts of data and users, where minimizing the cost per user is crucial. Or in other words, the vast majority of the current Web2 applications.

Brevis was the first to innovate beyond the traditional ZK Co-Processor model. Brevis created a "propose-challenge" architecture which significantly reduces costs and broadens the scope of applications that can be integrated into a ZK Co-Processor framework. This approach is similar to the finality confirmation process of Optimistic Roll-Ups, which involves directly submitting the co-processing results as a commitment which can subsequently be challenged by others using fraud proofs to ensure correctness. Note that Brevis differs from traditional Optimistic Roll-Ups in that the initial commitment is secured by a Proof of Stake network and the fraud proof challenge process is based on ZK instead of crypto-economic incentives used by most Optimistic Roll-Ups.

Currently, Brevis is the only player in the optimistic Co-Processor space, pioneering this new methodology to make ZK Co-Processors more practical and cost-effective for a wider range of applications.

Case Study: Brevis coChain
Brevis operates as an Eigenlayer AVS, whereby external operators (e.g. P2P, Allnodes) stake ETH and LSTs of ETH to gain the right to process and validate transactions on behalf of Brevis. To understand how the Brevis coChain functions, we delve into its architecture in more detail.
Request initiation: A smart contract sends a request to initiate the co-processing process (e.g. verify if a Uniswap user is eligible for a discount based on prior usage of the protocol).
Data extraction and result generation: Upon receiving the co-processing request, individual validators within Brevis coChain generate co-processing results based on raw data extracted from the corresponding blockchain’s archive nodes.
Consensus and proposal submission: After achieving PoS consensus among validators, Brevis coChain submits the results, along with a quorum of signatures, to the requesting blockchain in the form of a proposal.
Challenge and slashing window initiation: The proposal initiates two timers: an application-specified challenge window and a coChain slashing window. While the former is set by developers, the latter is set by the chain.

Exhibit 34: Brevis coChain Architecture

Challenge submission: Within this system, anyone can challenge a result by submitting a challenge claim along with a monetary bond on chain. Challengers do not need to present their challenge ZK proof immediately; they only need to declare the start of the challenge process on chain.
Challenge verification and finalization: The challenge ZKP is submitted, and the results are finalized. A successful challenge triggers an on-chain slashing event, penalizing malicious validators and rewarding the challenger. If a challenge fails, either due to a timeout of the proof submission window or by receiving a proof that does not meet the correctness requirements, the challenger’s bond is forfeited.
Extended slashing window: The Brevis coChain’s slashing window remains open as a system-wide parameter spanning multiple days. This means that even if an application has accepted a faulty result, as long as the slashing window has not expired, malicious validators can still be slashed and incorrect results rectified.

Advantages:
More flexibility of use cases: The Brevis coChain offers greater flexibility for various use cases, making it easier to prove that certain events did not occur, which is a computational struggle for ZK Co-Processors (see our previous example with regards to checking for OFAC-restricted interactions). Using ZKPs for this example is immensely expensive, making it impossible for Web3 applications to offer personalized services to their users. In addition, Brevis enables developers with “customisable finality times” allowing developers to set use case-specific challenge periods. For example, developers might want to set a short window for low-value or time-sensitive transactions, and a longer window for high-value, less time-sensitive transactions.


Faster processing: The Brevis coChain can process and verify transactions more quickly compared to computationally intensive ZKP-based methods.
Cost-effective: Using the Brevis coChain is more economical than relying solely on ZKPs, making it suitable for large-scale applications. This is because instead of asking to prove that something happened/did not happen like in ZK Co-Processors, they ask a committee of validators (who have value at stake) to agree if something happened/did not happen. If someone disagrees, only the challenger is required to send a single transaction proof (see Exhibit 33). Adding the PoS mechanism should reduce costs by ~90% according to the Brevis team itself.
Disadvantages:
New and untested design: The Brevis coChain is a relatively new and untested design which poses risks and uncertainties in its performance and reliability.
Potential slashing events: Validators in the quorum are subject to potential slashing events (financial penalties) if they are found to be acting maliciously or if their consensus is proven incorrect.
Next…
Having discussed ZK and Optimistic Co-Processors in Chapter 2, we will cover TEE and Crypto-economic Co-Processors in Chapter 3. At the same time, we will also be kicking-off Florin Digital’s Co-Processor podcast series, in which we will be interviewing leading actors in the Co-Processor space. The first guest will be Sylve from Hylé, a ZK-verification layer.
Come Say Hi
The Florin Digital team will be attending Selini Summit at the end of June as well as EthCC early July.
In Brussels we will be co-hosting drinks and a Co-Processor meet-up. Reach out and get in touch (Florian, James, Feyo) we would love to hear from you!
About Florin Digital

General Disclaimer
Florin Digital and its affiliates make no representation as to the accuracy or completeness of such information listed herein. These materials are not intended as a recommendation to purchase or sell any commodity, security, or asset. Florin Digital has no obligation to update, modify or amend this material or to otherwise notify any reader thereof of any changes.
This presentation and these materials are not an offer to sell securities of any investment fund or a solicitation of offers to buy any such securities. Any investment involves a high degree of risk. There is the possibility of loss, and all investment involves risk including the loss of principal.
Florin Digital LP and its affiliates may currently hold positions in tokens mentioned in this report, may have at one time held positions in tokens mentioned in this report, and may enter into spot, derivative, or other positions related to tokens mentioned herein.
Anything mentioned here should not be interpreted as a recommendation to purchase or sell any token, or to use any protocol listed, described, or discussed. The content of this report reflects the opinions of its authors and is presented for informational purposes only. This is not and should not be construed to be investment, tax, or legal advice.