
Chapter 1 - Verifiable Off-chain Compute: Enabling an Instagram-like experience for Web3
Chapter 1: What are Co-Processors and why do we need them?


Florian Unger (Principal, Florin Digital) | James Burkett (Partner, Florin Digital) | Feyo Sickinghe (Partner, Florin Digital)
A big thank you to @sylvechv for invaluable help, review, and feedback.
Chapter 1: What are Co-Processors and why do we need them?
Onboarding native users to blockchains and Crypto applications requires highly performant, data-rich applications just like we have grown accustomed to in Web2. These design limitations are generalized to blockchains and are a direct effect of the architecture of decentralized systems. Having spent significant time with founders and projects working to fix these performance issues, the solution has become clear: verifiable off-chain compute. We have summarized our learnings in a report: “Verifiable Off-chain compute - bringing an Instagram-like UX to Web3”.
Our findings will be released as a multi-chapter series in the upcoming weeks. Releases will be accompanied by interviews and podcasts from founders, builders, and investors in the space.
This is Chapter 1.
Table of Contents
Chapter 1: What are Co-Processors and why do we need them?
Why decentralized systems are bad at storage and high-performance compute
Why should we care about limited computation and storage?
Understanding computational and storage limitations on Ethereum and Solana
How can we make blockchains more performant?
What exactly are Co-Processors?
Chapter 2: Understanding the different types of Co-Processors
Chapter 3: Use cases of Co-Processors
Chapter 4: Open questions on the future of Co-Processors
Executive Summary:
Due to the nature of decentralized computing systems, all blockchain protocols struggle with data storage and high-performance computation
To build highly performant, elegant applications (Web3 with an Instagram-like experience), blockchains need data-heavy, high-performance computation
Blockchains can be made more performant in 2 key ways: increase hardware (“HW”) requirements to run them or outsource computation to “off-chain” providers
Off-chain compute will typically stretch existing trust assumptions, but Co-Processors presents an elegant solution in a verifiable and trust-minimized way
Why decentralized systems are bad at storage and high-performance compute
We have continuously heard of the benefits provided by decentralized systems compared to their centralized counterparts. In centralized systems, data is typically stored and managed in a single location rather than spread out across many. This represents a single point of failure (SPOF). If the single core system is hacked, it translates to losses for stakeholders that rely on it, as seen in the WannaCry 2017 attack, the Bangladesh Bank Heist 2016 or the Delta Airlines Hack of 2004.
In addition to the removal of a SPOF, many blockchains - which are in effect decentralized systems - rely on computation-limiting settings to theoretically prevent network abuse or distributed denial of service (DDoS) attacks (spamming a system until it fails). One key example is Ethereum, which charges “gas fees” for on-chain computation or Solana which limits the maximum compute per block and account. While the risk of DDoS attacks is - in theory - significantly reduced, we have seen several instances, such as DDoS attacks between competitors on Solana in April 2024.

Another key element of decentralized systems, or Multiple Point of Failure Systems, is the formation of agreement between different participants (computer nodes), aka reaching consensus on a status quo. In practice, this means that every node is voting on whether this is the accurate state of the database. We believe that reaching consensus on a global scale is important for some data components (i.e. ownership, money, law), yet less relevant for others (i.e. hotel booking) - please refer to Polynya’s post for additional information. To enable efficient and fast consensus, the amount of data that is being shared is usually kept to a bare minimum, consequently preventing high-data computation across distributed nodes.
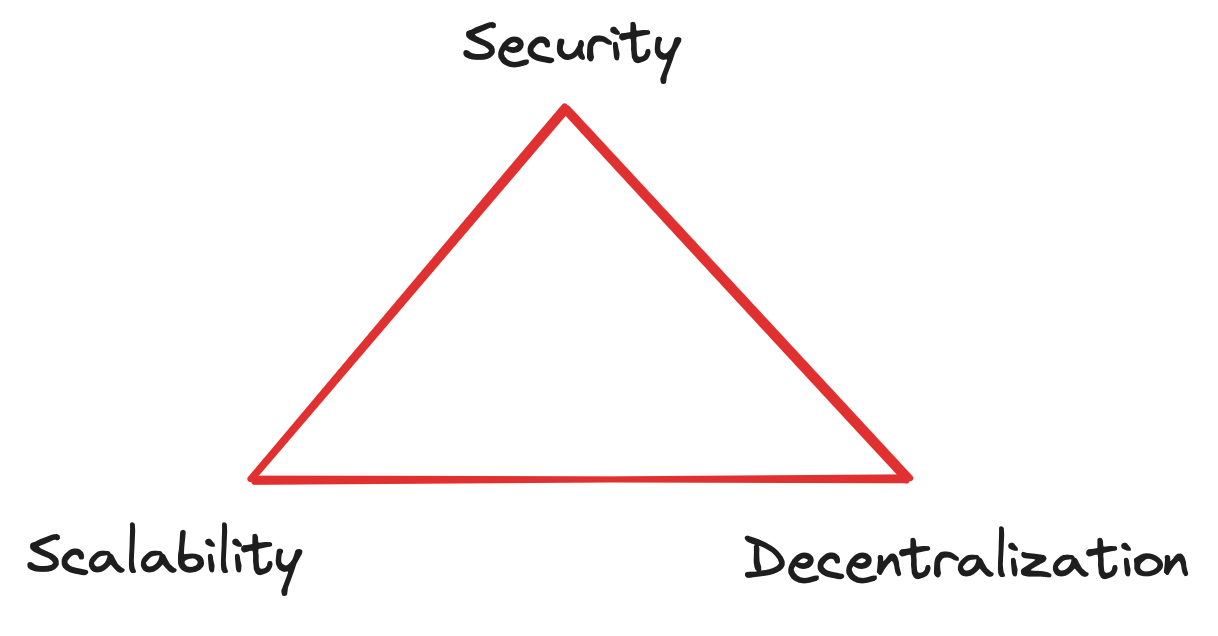
Therefore, the nature of decentralized systems makes it impractical to perform heavy computation with large amounts of data across multiple computer systems. This means that it is impossible to build Web3 applications with the “Instagram experience”. Within the crypto community, this issue is known as the “scalability trilemma,” referring to the trade-offs (between scalability, security and decentralization) of decentralized systems. The scalability trilemma is native to all decentralized system designs, ranging from highly decentralized blockchains such as Bitcoin and Ethereum to high-throughput designs like Solana. Again, and this is important to understand: the lack of scalability and the inability to have high-performant, data-rich compute is a natural problem of decentralized systems, and not specific to certain blockchain designs.
We believe that the limited computation and data storage capabilities are the key problems facing blockchains today. Many technologists, builders, ideologists and speculators have found their way to the crypto ecosystem today. However, to attract the next group of users, the industry needs to build easy-to-use, high-performance applications if it wants to have a chance at competing with existing Web2 applications. In short, Crypto needs to empower Web3 applications with the ability to build an Instagram-like UX.
Why should we care about limited computation and storage?
In the last decade, the shrinking cost of compute paired with the rise of data availability has led to data-rich web and mobile applications. These traits helped propel penetration of the internet to nearly 70% of the World’s population, or 5.5bn users, in 2023. The vast majority of these users have become accustomed to a minimum standard when it comes to performance and user experience, a minimum standard which is generally hard to replicate using today’s Crypto infrastructure. So how did Web2 develop the infrastructure to build powerful, data-rich applications?
In the past decade, several computational trends have significantly increased the capabilities of computing. Technological advancements in cloud computing, such as containerization, serverless computing, and high-performance computing (HPC), have revolutionized the way applications are deployed. The cost of compute has dropped dramatically. CPU computing is between 10 and 1,000 times cheaper than it was two decades ago, with GPU computing costs reduced by 100 times (Coyle and Hampton, 2023). Cloud computing costs have similarly fallen by ~ 90% from 2013 to 2023. Residential internet speeds have also seen remarkable improvements, increasing from an average of 9Mbps in 2010 to 100Mbps in 2023, supporting more data-rich applications. In addition, the transition from 3G to 4G mobile networks offered a tenfold increase in mobile internet speed, boosting download speeds from 1.5Mbps to 15Mbps - downloading a 800MB movie now takes 43 seconds on 4G vs. 5h on 3G in 2014.
As internet speeds increased and computing costs decreased, the creation and utilization of data grew exponentially. In 2010, the world created 2 zettabytes of data. This is expected to increase to 147 zettabytes, 87x growth, in 2024. The surge in the amount of data generated coincides with increasing usage of that data. In Western Europe, the average mobile data usage per smartphone rose from 6GB/month in 2018 to 33GB/month in 2024.

The increase in data usage comes from the increasingly complex and data rich applications. The average mobile game has grown from approximately 50MB in 2011 to well over 5GB in 2023.

Today’s consumers expect new applications to meet or exceed these quality/product standards, there is no reason to sacrifice quality that is readily available. Any Crypto application that offers less in terms of quality, data richness, or performance is highly unlikely to replace what already exists today.
As of today, there are around 580 million Web3/Crypto owners globally (Facebook on the other hand has over 3 billion global users). Most of these Web3 users are ideologists who prioritize concepts such as censorship resistance over the seamless user experience offered by Web2 applications. Their motivation for accessing global, uncensored Web3 applications outweighs the importance of user-friendly interfaces. However, if Crypto is to grow, it needs to be able to onboard new users beyond those that are purely driven by ideology. The reason is straightforward: everyday internet users do not prioritize blockchain benefits over performance. They are not ideologists, nor do they need to be. They just want to use top-notch products.
“If ideology isn’t a driver, why do we need Crypto when we already have high performance apps in Web2?” we hear you say. Blockchains perform a number of functions, but at the very core, they produce “trust” at the lowest marginal cost. And therefore, they have the potential to vastly improve all sorts of existing products and services built in industries which suffer from a high number of rent-seeking (and regulated) intermediaries. In other words industries with a high “cost of trust”.
Whilst the majority of blockchain scaling initiatives to date have focused on increasing throughput i.e. increasing the number of transactions per second, a relatively small amount of effort has been put into improving the user experience. This is why Crypto applications don’t have data-rich features such as content personalisation, responsive design, interactive elements, direct user feedback and deep integrations with other apps. However, in order to grow the Crypto ecosystem from here, we need to onboard mainstream users, and mainstream users deeply care about UI/UX and customized product features — all of which require substantial compute power as well as access to historical data and storage. Current Crypto protocols cannot offer app developers the necessary tools to build applications that rival current Web2 products. Thus, without compelling products, Crypto applications will struggle to onboard the coveted “next billion” users.

So what can we do about it? From a technical perspective, certain compute operations are relatively cheap to perform on decentralized systems such as Ethereum (e.g. Keccak-Hash, some Elliptic Curve operations, and ECDSA signatures). Others are prohibitively expensive (like Ed25519, complex numerical functions, or ML operations). This means that complex applications like machine-learning models, games, or scientific computing applications cannot run on a blockchain at present. As a result, current Crypto applications cannot match the data-rich and compute-heavy quality of Web2 products, making it increasingly difficult for decentralized systems to compete for users.
Understanding computational and storage limitations on Ethereum and Solana
Comparing compute
Why is compute important? Different blockchains exhibit varying degrees of decentralization. Ethereum, notably, advocates for decentralization above all else, optimizing for censorship resistance, security and uptime. It can “...simultaneously live in all the nodes of an enormous global network, which would be able to process anything you threw at it, without downtime or interference, so developers could build whatever they dreamed of, and nobody would be able to stop them or their applications. Like an infinite machine.” While this sounds like a noble mission, decentralization itself remains a nebulous concept (Walch, 2019). The term can range from geographical decentralization and client diversity to token distribution, developer activity affiliation, governance affiliation, RPC and Oracle decentralization and so on. While we will not dive into this here, more on the topic can be found here: (Decentralisation is good or not?), here (Measuring blockchain decentralization) and here (The near and mid-term future of improving the Ethereum network's permissionlessness and decentralization).
For the purposes of this piece, we will use the number of full nodes which vote on consensus as a measure for decentralization - the most commonly used metric for Proof of Stake (PoS) networks. In the case of Ethereum, full nodes participate in the consensus finding process whereas light or archive nodes do not. As of June 2024, Ethereum has ~6,000 full nodes across the globe. To run a full node, one needs specific hardware (fast CPU with 4+ cores, 16GB of RAM, a fast SSD drive with at least 1TB of space and 25MBit/s bandwidth). This means a full node can be run on a Raspberry Pi (for non-geeks, this is a simple, very small Linux computer that fits in a handbag) with an external storage unit. While the $80-100 cost for it might seem low for the majority of the developed world, it does present a significant challenge for lower-income users to participate in global consensus, arguably leading to some form of economic centralisation. Due to the low minimum computational requirements of full nodes and the fact that the network is only as strong as the weakest node, network performance is fairly limited.

To accommodate the low computational throughput and high full node decentralization, Ethereum produces blocks sized between 1-5MB every 12 seconds, enabling 15 transactions per second (TPS). Ethereum uses “gas”, referring to the unit that measures the amount of computational effort required to execute specific operations on the Ethereum network. Gas is paid in native ETH tokens with users paying a certain amount of gas for their transaction to be included in the next block. Currently, a standard ETH transfer requires a minimum of 21,000 units of gas, which translates to a transaction fee of 0.000336 ETH / $1.29 during periods where the gas price is relatively low (e.g. 14 gwei).
Why 21,000? This covers the cost of an elliptic curve operation to recover the sender address from the signature as well as the disk and bandwidth space to store the transaction (see here for more details on how transaction costs are calculated).
Ethereum also has a current targeted size of 15 million gas per block. The size of blocks will increase or decrease in accordance with network demand, up until the block limit of 30 million gas (2x the target block size). Gas limit per block has gradually increased from 5,000 gas per block in 2015. The price of a transaction depends on the number of gas units used (i.e. the computational complexity) and the current gas price (economical demand driven metric). Currently, there are ongoing discussions to increase the gas limit yet again to 40-45 million. Any change in the gas limit per block simply pushes up the hardware requirements to operate an Ethereum node. To stay within the stated limit of 30 million gas limit per block, the Ethereum Virtual Machine (EVM) - essentially the computer running on top of the blockchain - restricts certain functionalities to keep the full chain lighter weight. For example, the EVM restricts floating-point math operations while supporting only basic mathematical and logical operations instead.
This limitation means that numerical calculations, such as those required for machine learning models (e.g. to predict user behavior) cannot be run. If you want to use AI in your application, you're out of luck on this one. The EVM also has limited pre-compiles. At a high level, pre-compiles determine the functionality of the EVM. They are built-in functions that allow smart contracts to be translated down to the EVM so they can actually be executed. The more pre-compiles allowed, the greater the Ethereum design space. However, adding pre-compiles on Ethereum is extremely complicated, as it opens up the network to new attack vectors and complicates the EVM and its maintenance.
On the compute side, Solana has taken a different approach, favoring scalability by requiring consensus nodes to run higher-performance hardware (HW). Concretely, the HW requirements are 256GB of RAM with a 512GB motherboard. In contrast, an iPhone 15 has 6GB of RAM while Ethereum’s full/archive nodes require 16GB RAM, meaning Solana’s HW requirements are 42x and 16x higher, respectively. These limitations generally prohibit everyday users from participating in the network by running nodes, leaving this task to professional operators alone. This design choice however significantly enhances performance. Solana achieves both faster block times, 400 milliseconds vs 12 seconds, and significantly higher transactions per second (max. recorded TPS on Solana is 1,624 vs. 62 on Ethereum). Still, Solana also faces clear storage and compute limitations.

On Solana, each transaction incurs a base fee (paid in SOL). Solana’s base fee is a fixed fee of 5,000 lamports (0.000005 SOL) per signature with most transactions having one signature (maximum is 12 signatures per tx). The more signatures, the higher the Solana base fee. This fee is mandatory for all transactions and covers the basic cost of processing the transaction on the network. Compute Units (“CUs”) measure the computational resources required for a transaction. Similar to "gas" on Ethereum, CUs are used to quantify the complexity and resource consumption of a transaction.

Every transaction, whether it uses priority fees or not, consumes CUs. The base fee includes a certain amount of CUs to cover computational tasks, plus any additional fees for faster block inclusion. These priority fees are directly linked to the additional compute units a transaction consumes, ensuring it is processed more quickly by “bribing” block producers. Unlike Ethereum which only has a targeted limit size, Solana has a maximum compute limit of 48 million CUs per block, 12 million CU per account and 1.4 million CU per transaction. Keeping a program's compute usage within these limits is crucial to ensure timely execution at a reasonable cost.

Looking at the difference between the cost of executing a swap on Ethereum vs. Solana ($7.5 on Ethereum vs. $0.01 on Solana) begs the question as to why the Solana Virtual Machine (SVM) is more efficient than the EVM.

The EVM is not able to parallelize transaction processing and must sort and settle transactions one by one. Since contract operations do not need to handle data storage, the EVM does not know which data on the chain will be modified before execution. Everything only becomes clear after execution, which prevents the EVM from parallelizing transaction processing. Otherwise, it may result in awkward situations in which two transactions attempt to modify the same data simultaneously.
SVM’s focus is on separating the execution program and data storage which allows for parallel processing. Solana’s runtime knows all the accounts (which store the state) that will be used in a transaction before processing it. So, if two transactions do not access the same account, they can be processed in parallel, leading to higher TPS and lower cost per transaction. While we will not get into it here, more can be found at these sources: (Comparison Between EVM, Solana Runtime, MoveVM) and here (What Is SVM - The Solana Virtual Machine).
Comparing data storage
From a data storage perspective, Ethereum uses full nodes and archive nodes. Full nodes participate in the Ethereum consensus and require 16GB of RAM and a fast SSD drive with at least 1TB of space. Focusing on short-term memory, they store and query recent block data (i.e. the last 128 blocks) with a maximum storage capacity of 512GB.

Any history beyond that (aka long-term memory) is stored on off-chain archive nodes, de facto semi-centralized off-chain databases. Archive nodes are useful when querying historical blockchain data that is not accessible on full nodes. Even though they are operated by semi-centralised off-chain databases, data requesters usually choose to trust the historical data coming from archive nodes as re-computation is too expensive. They have similar HW requirements as full nodes, yet are required to have higher SSD storage of 13TB. However, even with archive nodes, storing 1GB of data on Ethereum can cost anywhere up to $60m, depending on gas costs. As a direct practical comparison, storing 1GB on Google Cloud costs $0.27. For Ethereum this means that running data-heavy computations which require substantial on-chain storage are not feasible.
On Solana, blockchain state is stored in accounts which hold data and smart contracts. Each account can store a variety of data, including user balances and contract state. Solana’s validator nodes (256GB RAM and 2TB SSD) process transactions and add them to the blockchain, with each validator storing a copy of the ledger that includes all transactions and the current state of all accounts.
So how do you store 4 petabytes of data every year at full capacity? Solana utilizes a technique called "horizontal scaling" to distribute data across multiple validators, enhancing efficiency and speed. Instead of having archive nodes like Ethereum, Solana employs a decentralized storage protocol (Arweave) for off-chain historical data storage. This approach ensures data remains accessible without overburdening validators.

Another key feature of Solana is its "Proof of History" (PoH) mechanism, which timestamps transactions, creating a verifiable order and reducing the need for extensive historical data storage on-chain. Validators also periodically take snapshots of the ledger's state, allowing new validators to quickly catch up to the current state without processing the entire transaction history. Despite all the improvements in storage architecture versus Ethereum, storing 1GB of data on-chain remains expensive, costing up to $10m. While this represents a c. 10x improvement over Ethereum, it is still infinitely more expensive compared to Google Cloud.
Despite the significant architectural improvements of Solana, storage and compute limitations remain an issue. These compute and storage issues are inherent to decentralized systems and blockchains, not any specific blockchain.
How can we make blockchains more performant?
There are solutions to enhance blockchain performance, namely adding more storage space and compute power. This can be accomplished by increasing HW requirements to outsourcing computation and storage via a so-called “off-chain” solution.
Option 1 - Increasing HW requirements:
We can increase the node requirements for existing blockchains, seen in Solana vs. Ethereum. Solana validator nodes have 16x higher RAM than Ethereum nodes. This approach is relatively common among high-throughput blockchains like Aptos, Sui, Sei, and Solana, which focus more on scalability and less on widespread consensus and node decentralization.
However, by increasing hardware requirements, one sacrifices decentralization. For example, Solana has increased its median RAM requirements from 64GB in 2020 to 256GB in 2023. For comparison, my MacBook Air with an Apple M2 chip has 8GB of RAM, making it impossible to monitor the Solana network and participate in the consensus process via a low-cost device such as a laptop, a Raspberry Pi or a mobile phone.

While it is possible to increase hardware requirements as more powerful chips come to market, we can already see quite clearly how some high-performance applications on Solana (i.e. AI training) will outstrip existing hardware solutions. Thus we believe that increasing baseline node requirements presents only a temporary, short-term solution, which does not address mid-to-long-term compute and storage needs. Additionally, by further increasing on-chain compute and storage capacity, blockchains inevitably reduce an application’s flexibility around compute and data privacy (e.g. max CU per transaction on Solana).
Option 2 - Outsourcing compute to an off-chain actor:
Given the limitations of enhancing on-chain performance, compute and storage could simply be moved “somewhere else” (to an off-chain actor). To be clear, this is how excessive compute requirements are handled today. This has also been the approach for compute and storage limitations in traditional compute for the past 50 years. In the 1970s, computation environments addressed the need for additional compute by installing another processor alongside the main processor - the so-called Co-Processor. Co-Processors were invented to offload specialized tasks such as floating-point arithmetic (e.g. Intel 8087), graphics, signal processing, string processing, or I/O interfacing. Offloading these functions to “someone else”, allowed the main processor to focus on general compute tasks. This division of labor led to significant performance improvements. Today, literally every computational environment - from your phone to your computer - has Co-Processors installed.

As the processor and the Co-Processor were part of the same compute system (from the same HW developer), they interacted with each other in a - more or less - trustless way. How do you create this trustless relationship if there are two different computation systems? We will come back to that in a bit.

Option 2a - External off-chain compute by a Trusted Actor (i.e. Cloud providers):
When discussing off-loading compute, cloud computing (i.e. AWS, Azure) is the first thing that comes to mind. One example would be AWS Lambda, which allows applications to run heavy compute operations in the cloud serverlessly. While cloud computing has been a game-changer for start-ups, it invalidates Crypto’s trustlessness assumption.
To recap the trustlessness assumption in layman terms: in the realm of blockchains, we want to be certain that "someone else" did not cheat or act maliciously. Or how Starknet founder Eli Ben Sasson puts it eloquently, ”someone did the right thing even if you were not looking”. With cloud computing, applications must trust that cloud compute providers perform tasks as stated (using agreed-upon LLMs, GPU, latency, etc.). These providers operate within an opaque black-box environment outside the blockchain. Thus, while AWS offers a short-term fix, it significantly undermines the verifiability requirement of trustless networks like blockchains.

With the rise of ubiquitous data, ML, and AI, trustlessness becomes paramount. For example, developers must know that the correct dataset has been used to train the model as retraining is prohibitively expensive. The ability to verify compute accuracy and validity goes from a “nice-to-have” to table stakes.
Option 2b - Off-chain compute by a stateful, trustless actor (roll-ups):
Roll-ups have become increasingly popular in the crypto space, emerging as the preferred solution to scale Ethereum’s execution. Roll-ups are defined as blockchains that post their blocks of executed transactions to another blockchain, thereby inheriting the consensus and data availability (DA) of that blockchain. In simpler terms, they are external computers that execute transactions (hence the term execution roll-ups) using separate compute and storage resources (state) to post batches of transactions and their data onto Ethereum. To verify that the transactions have been executed and batched correctly, they provide some form of “fraud” or “validity” proof to ensure legitimacy. While roll-ups have become very popular over the last 3-4 years, developers are becoming increasingly aware of the tradeoffs that they present.
The key problem roll-ups face is that applications are bound by their architectural setup. For example, imagine that someone wants to build a fast-moving betting market on Starknet, a validity proof roll-up on Ethereum. Users of the app might bet on a time-sensitive outcome (e.g. a goal in the 90th minute), requiring fast transaction throughput. On Starknet, the transaction execution takes approximately 15 seconds, proving the transaction takes 2 minutes, while the verification on Ethereum L1 (aka finality) can take around 10 hours. In other words - even with an execution time of 15 seconds, time-sensitive products will struggle on Starknet.

Finality on an Optimistic roll-up can even take up to 7 days. This is due to the challenge period imposed, despite the fact data is posted back to Ethereum every 2-3 minutes. From our conversations with developers, we often hear the analogy that roll-ups are like buses—they get you to the destination, but offer limited flexibility in terms of the journey, i.e. settlement times, execution finality, and data availability.
So as an app, why not create your own roll-up, if the application design space is limited by roll-up constraints? This is increasingly becoming a viable option, a huge positive. From a business perspective it seems sensible too, as it allows for more customization and better value capture of fees generated. However, there are some downsides for the wider ecosystem and therefore the end-user, notably further fragmentation of liquidity within the Ethereum ecosystem. Fragmented liquidity is a problem caused by roll-ups and can be compared to someone having >20 independent, non-connected accounts at the same bank, making it impossible to take out - for example - a loan using total net worth as aggregate collateral.

Furthermore, creating a personalized roll-up for each application is also tiresome and duplicative as it shifts the focus from building an application to building a complete compute infrastructure. This is something app developers rarely want to do, especially if they are coming from Web2, where the compute infrastructure is plug-and-play.
What exactly are Co-Processors?
Roll-ups are like buses, they bring passengers (transactions) to their final destination (settlement finality on Ethereum) and increase the overall throughput of the highway (scalability of Ethereum). However, passengers have limited flexibility regarding arrival times (execution and settlement finality) and their luggage (compute/data per transaction). Roll-ups are a good solution for the vast majority of transactions as they batch transactions thereby distributing the cost before posting the data to Ethereum. But what if you want to have more flexibility in terms of execution, settlement finality and compute/data input per transaction, while also preventing the liquidity fragmentation caused by roll-ups?
Welcome to the simple, elegant (yet, surprisingly unhyped) realm of Co-Processors! A solution, which has been around in the compute space since the 1970s. In the context of Crypto, Co-Processors provide stateless, off-chain computation in a verifiable and transparent manner. Stateless means that the off-chain compute provider does not store previous transactions (unlike roll-ups which store state). Co-processors compute single transactions or computations (e.g. ML models, LLM inference) off-chain before sending the corresponding result on-chain. This is in stark contrast to roll-ups, which compute several transactions and batch them together before posting them on-chain.

So, how do they work? A request is issued to the off-chain compute provider, who processes the request and sends the result, along with some form of verification of correct computation, back to the on-chain smart contract.

In the crypto world, the term Co-Processor was (re)introduced by Axiom in Q4 2022 with the idea of giving smart contracts additional functionality. Axiom’s first product provided smart contracts with trustless processing access to Ethereum’s historical data, which is the data stored by trusted archive nodes. This meant that smart contracts could query Axiom on-chain to perform trustless historic data reads and computations over historical Ethereum data, something that was not available previously. This means that Axiom generated the results off-chain and provided a Zero-Knowledge Proof (ZKP), which is a type of validity proof, to verify the correctness of the computation on-chain. Axiom acts as the co-processor, providing a specialized service to the main processor, Ethereum.
Traditionally, Co-Processors do not have state (thus they are “stateless”) though exceptions exist and these will be discussed in subsequent parts of this report. By being stateless, Co-Processors offer significantly higher flexibility compared to roll-ups, and can be easily integrated into existing blockchains as they settle directly onto the base layer (Ethereum). Since Co-Processors perform work off-chain, they must be able to prove verifiability and correctness on-chain. This can be achieved in two ways primarily:
Crypto-economics: Using economic incentives to ensure the off-chain compute provider does not cheat by requiring an economic stake that can be forfeited.
Cryptographic correctness: Using mathematics and cryptography to ensure the off-chain compute provider does not cheat through methods like Zero-Knowledge Proofs (ZKPs), Fraud Proofs, or Trusted Execution Environments (TEEs).

Next…
We will continue to explore different approaches for Web3 applications to recreate an “Instagram experience” in more detail in subsequent releases. Subscribe below and follow along with additional writing, podcasts, and in-depth interviews.
About Florin Digital

General Disclaimer
Florin Digital and its affiliates make no representation as to the accuracy or completeness of such information listed herein. These materials are not intended as a recommendation to purchase or sell any commodity, security, or asset. Florin Digital has no obligation to update, modify or amend this material or to otherwise notify any reader thereof of any changes.
This presentation and these materials are not an offer to sell securities of any investment fund or a solicitation of offers to buy any such securities. Any investment involves a high degree of risk. There is the possibility of loss, and all investment involves risk including the loss of principal.
 | A guest post by
|